

당신의 첫 ‘금융 AI 포트폴리오’, 1시간 만에 완성시켜 드립니다.
파이썬 AI 주가 예측 모델 만들기
“파이썬은 좀 다룰 줄 아는데, 이걸로 뭘 해야 할지 막막해요.” “금융권 취업을 위해 AI 프로젝트 경험이 필요한데, 어디서부터 시작해야 할지 모르겠어요.”
만약 위와 같은 고민을 하고 있다면, 정말 잘 찾아오셨습니다. 이 글은 복잡한 이론은 잠시 접어두고, 당신이 직접 코드를 실행하며 눈으로 결과를 확인하는 ‘실습’에 모든 초점을 맞춘 A to Z 튜토리얼입니다.
이 가이드 하나만 처음부터 끝까지 따라오시면, 여러분은 텐서플로우(TensorFlow)의 LSTM 모델을 활용하여 주가를 예측하고, 가상 매매를 통해 수익률까지 검증하는 완성된 ‘AI 주가 예측 모델’을 갖게 될 것입니다.
이 프로젝트는 단순히 코딩 연습에서 그치지 않습니다. ‘퀀트 투자 파이썬’의 세계에 첫발을 내딛는 경험이자, 당신의 ‘금융 데이터 분석 AI’ 역량을 증명해 줄 훌륭한 포트폴리오가 될 것입니다.
왜 하필 ‘LSTM’ 모델을 사용할까요?
주가 예측에는 수많은 AI 모델이 사용될 수 있습니다. 그중에서도 RNN(순환 신경망)의 한 종류인 LSTM(Long Short-Term Memory)이 자주 사용되는 이유는 무엇일까요?
가장 쉽게 비유하자면, LSTM은 ‘기억력이 매우 좋은 투자 전문가’와 같습니다.
단순한 모델은 어제의 주가만 보고 오늘의 주가를 예측하려 합니다. 하지만 노련한 투자 전문가는 며칠 전, 몇 주 전의 주가 흐름과 시장 분위기까지 기억하며 종합적으로 판단하죠.
LSTM이 바로 그 역할을 합니다. 과거의 수많은 데이터 중에서 어떤 정보가 중요하고(Long-Term), 어떤 정보는 잊어도 되는지(Short-Term)를 스스로 학습하여 ‘기억’합니다. 이러한 특성 덕분에 주가처럼 시간의 흐름에 따라 데이터가 쌓이는 시계열 데이터 분석에 매우 강력한 성능을 보여줍니다.
이제, 이 똑똑한 전문가를 직접 만들어볼 시간입니다.
AI 주가 예측 모델 만들기: 7단계 실전 가이드

지금부터 딱 7단계만 따라오시면 모델이 완성됩니다. 각 단계의 코드는 그대로 복사해서 붙여넣기만 하면 바로 실행됩니다.
1단계: 개발 환경 설정
가장 먼저 필요한 도구(라이브러리)들을 설치해야 합니다. 터미널 또는 명령 프롬프트에 아래 명령어를 입력해 주세요.
pip install tensorflow pandas numpy matplotlib yfinance scikit-learn
- tensorflow: 구글이 만든 핵심 AI 개발 라이브러리입니다.
- pandas & numpy: 데이터를 다루고 계산하기 위한 필수 라이브러리입니다.
- matplotlib: 데이터와 결과를 그래프로 그리기 위해 사용합니다.
- yfinance: 야후 파이낸스에서 주가 데이터를 쉽게 가져올 수 있게 해줍니다.
- scikit-learn: 데이터 전처리(정규화)를 위해 사용합니다.
2단계: 주가 데이터 불러오기
yfinance를 이용해 삼성전자(종목코드: 005930.KS)의 주가 데이터를 불러오겠습니다.
import yfinance as yf
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# 1. 데이터 불러오기 (삼성전자, 2020-01-01 ~ 2023-12-31)
ticker = "005930.KS"
data = yf.download(ticker, start="2020-01-01", end="2023-12-31")
# 종가(Close) 데이터만 사용
close_data = data[['Close']].values
print(data.head())
yf.download(): 지정한 종목코드와 기간의 주가 데이터를 다운로드합니다.data[['Close']].values: 여러 데이터(시가, 고가, 저가 등) 중 예측의 기준이 될 ‘종가’ 데이터만 선택합니다.
3단계: 데이터 전처리 (가장 중요!)
AI 모델이 데이터를 잘 학습할 수 있도록 ‘밥상’을 차려주는 과정입니다.
# 2. 데이터 정규화 (0과 1 사이의 값으로 변환)
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(close_data)
# 3. 훈련 데이터와 테스트 데이터 분리 (80% 훈련, 20% 테스트)
train_size = int(len(scaled_data) * 0.8)
train_data = scaled_data[:train_size]
test_data = scaled_data[train_size:]
# 4. 시계열 데이터셋 생성 함수
def create_dataset(dataset, time_step=60):
X, Y = [], []
for i in range(len(dataset) - time_step - 1):
a = dataset[i:(i + time_step), 0]
X.append(a)
Y.append(dataset[i + time_step, 0])
return np.array(X), np.array(Y)
time_step = 60 # 과거 60일의 데이터를 기반으로 다음 날을 예측
X_train, y_train = create_dataset(train_data, time_step)
X_test, y_test = create_dataset(test_data, time_step)
# LSTM 모델에 입력하기 위해 데이터 형태 변환 (samples, time_steps, features)
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
- 정규화 (MinMaxScaler): 모든 데이터 값을 0과 1 사이로 압축합니다. 데이터의 크기 차이가 너무 크면 모델 학습이 불안정해지기 때문에 안정적인 학습을 위해 꼭 필요합니다.
- 훈련/테스트 분리: 모델을 학습시킬 데이터(훈련)와 학습이 끝난 모델의 성능을 평가할 데이터(테스트)로 나눕니다.
- 시계열 데이터셋 생성: ‘과거 60일의 주가(X)를 보고 다음 날의 주가(Y)를 맞추는’ 문제 형태로 데이터를 가공합니다.
4단계: LSTM 모델 설계 및 컴파일
이제 본격적으로 LSTM 주가 예측 모델의 뼈대를 만듭니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout
# 5. LSTM 모델 구성
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(time_step, 1)))
model.add(Dropout(0.2))
model.add(LSTM(50, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(25))
model.add(Dense(1))
# 6. 모델 컴파일
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
Sequential(): 케라스(Keras)에서 모델을 층층이 쌓아 올릴 때 사용합니다.LSTM(50, ...): 50개의 기억 셀(뉴런)을 가진 LSTM 층을 추가합니다.input_shape는 입력 데이터의 형태(60일, 1개 특성)를 의미합니다.Dropout(0.2): 학습 과정에서 일부러 20%의 뉴런을 껐다 켜면서, 모델이 훈련 데이터에만 너무 과하게 적응(과적합)하는 것을 방지합니다.Dense(1): 최종적으로 1개의 결과(다음 날의 주가)를 출력하는 층입니다.model.compile(): 만든 모델에 어떤 최적화 방법(adam)과 손실 함수(mean_squared_error)를 사용할지 설정합니다.
5단계: 모델 학습 및 성능 검증
설계한 모델에 훈련 데이터를 넣어 AI를 학습시킵니다.
# 7. 모델 학습
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=100, batch_size=64, verbose=1)
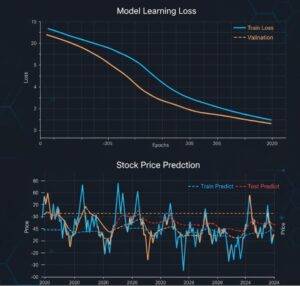
# 학습 손실 시각화
plt.plot(history.history['loss'], label='train loss')
plt.plot(history.history['val_loss'], label='validation loss')
plt.title('Model Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
model.fit(): 훈련 데이터(X_train,y_train)를 가지고 모델을 학습시킵니다.epochs=100: 전체 훈련 데이터를 총 100번 반복해서 학습합니다.- 손실 그래프: 학습이 진행될수록 모델이 정답에 가까워지면서 손실(오차) 값이 점점 줄어드는 것을 확인할 수 있습니다.
train loss와val_loss가 모두 안정적으로 감소하면 학습이 잘 된 것입니다.
6단계: 예측 결과 확인
학습된 모델이 테스트 데이터를 얼마나 잘 예측하는지 확인하고, 실제 값과 그래프로 비교해 봅니다.
# 8. 예측 수행
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# 9. 예측 결과 정규화 되돌리기
train_predict = scaler.inverse_transform(train_predict)
y_train_orig = scaler.inverse_transform(y_train.reshape(-1, 1))
test_predict = scaler.inverse_transform(test_predict)
y_test_orig = scaler.inverse_transform(y_test.reshape(-1, 1))
# 10. 예측 결과 시각화
plt.figure(figsize=(12,6))
plt.plot(data.index, data['Close'], label='Actual Price')
# 훈련 데이터 예측 결과 플롯
train_predict_plot = np.empty_like(close_data)
train_predict_plot[:, :] = np.nan
train_predict_plot[time_step:len(train_predict)+time_step, :] = train_predict
plt.plot(data.index, train_predict_plot, label='Train Predict')
# 테스트 데이터 예측 결과 플롯
test_predict_plot = np.empty_like(close_data)
test_predict_plot[:, :] = np.nan
test_predict_plot[len(train_predict)+(time_step*2)+1:len(close_data)-1, :] = test_predict
plt.plot(data.index, test_predict_plot, label='Test Predict')
plt.title('Stock Price Prediction')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
model.predict(): 학습된 모델로 미래 주가를 예측합니다.scaler.inverse_transform(): 모델이 예측한 값은 0과 1 사이로 정규화된 값이므로, 원래의 주가 단위로 되돌립니다.- 결과 그래프: 실제 주가(파란색)의 흐름을 예측 주가(주황색)가 꽤 유사하게 따라가는 것을 볼 수 있습니다.
7단계: 간단한 투자 백테스팅
이제 예측 결과를 바탕으로 간단한 매매 시뮬레이션(백테스팅)을 통해 수익률을 확인해 봅시다.
전략: AI가 내일 주가가 오늘보다 오를 것이라고 예측하면 ‘매수’, 아니면 ‘보유’
# 11. 간단한 투자 백테스팅
test_start_index = len(train_data) + time_step + 1
actual_prices = scaler.inverse_transform(test_data[time_step+1:])
predicted_prices = test_predict
# 투자 시뮬레이션
initial_capital = 10000000 # 초기 자본금 1천만원
capital = initial_capital
shares = 0
portfolio_values = []
for i in range(len(predicted_prices) - 1):
# 다음 날 가격이 오를 것으로 예측되면
if predicted_prices[i+1] > actual_prices[i]:
# 보유 현금으로 살 수 있는 만큼 최대한 매수
if capital > 0:
shares_to_buy = capital // actual_prices[i]
shares += shares_to_buy
capital -= shares_to_buy * actual_prices[i]
# 다음 날 가격이 내릴 것으로 예측되면
elif predicted_prices[i+1] < actual_prices[i]:
# 보유 주식 전량 매도
if shares > 0:
capital += shares * actual_prices[i]
shares = 0
# 현재 포트폴리오 가치 계산
current_value = capital + shares * actual_prices[i]
portfolio_values.append(current_value)
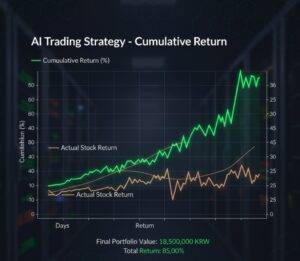
# 누적 수익률 계산 및 시각화
portfolio_df = pd.DataFrame(portfolio_values, columns=['Portfolio Value'])
portfolio_df['Daily Return'] = portfolio_df['Portfolio Value'].pct_change()
portfolio_df['Cumulative Return'] = (1 + portfolio_df['Daily Return']).cumprod() - 1
plt.figure(figsize=(10, 5))
plt.plot(portfolio_df['Cumulative Return'] * 100)
plt.title('AI Trading Strategy - Cumulative Return')
plt.xlabel('Days')
plt.ylabel('Return (%)')
plt.grid(True)
plt.show()
print(f"Final Portfolio Value: {portfolio_values[-1]:,.0f} KRW")
print(f"Total Return: {((portfolio_values[-1] / initial_capital) - 1) * 100:.2f}%")
- 매매 로직: 다음 날 예측 가격(
predicted_prices[i+1])이 오늘의 실제 가격(actual_prices[i])보다 높으면 매수하고, 낮으면 매도하는 간단한 전략입니다. - 누적 수익률 그래프: 이 전략으로 투자했을 때, 시간이 지남에 따라 자산이 어떻게 변하는지를 보여줍니다.
결론: 이제 당신의 가능성을 증명할 시간입니다.
축하합니다! 여러분은 방금 ‘AI 주가 예측 모델’을 직접 만들고, 심지어 투자 시뮬레이션까지 완료했습니다. 이 모든 과정이 담긴 코드는 여러분의 소중한 자산이자, 역량을 보여주는 훌륭한 증거입니다.
💻 전체 소스코드 다시보기 (GitHub)
물론, 이 모델이 완벽하지는 않습니다. 하지만 중요한 것은 ‘완성’의 경험입니다. 오늘 만든 모델을 기반으로 예측 기간을 바꿔보거나, 다른 종목의 데이터를 넣어보거나, 더 복잡한 모델 구조를 시도해보는 등 자신만의 프로젝트로 발전시켜 보세요.
⚠️ 중요: 투자 경고 및 모델의 한계
본 모델은 교육 및 학습 목적으로 제작되었으며, 실제 투자의 수익을 절대로 보장하지 않습니다. 주가는 갑작스러운 경제 뉴스, 시장 참여자들의 심리, 예측 불가능한 사건 등 AI 모델이 학습하지 못한 수많은 변수에 의해 영향을 받습니다. 실제 투자 결정에 대한 모든 책임은 투자자 본인에게 있습니다.
이제 첫걸음을 뗐으니, 두려워 말고 ‘퀀트 투자 파이썬’의 세계를 마음껏 탐험하시길 바랍니다.
삶을 풍요롭게 만드는 모든 것에 관심이 많은 큐레이터, [jeybee]입니다. 여행, 기술, 라이프스타일의 경계를 넘나들며, 직접 경험하고 엄선한 좋은 것들만 모아 여러분의 일상에 제안합니다.